A maioria dos métodos determinísticos de solução única são baseados em buscas. Dentre eles, a maioria possui duas abordagens: para frente ( botton-up) e para trás ( top-down). Na abordagem para frente,
inicia-se com um conjunto de avaliação (temporário) vazio e, conforme o algoritmo é executado,
são inseridas características nesse conjunto, até que esse fique com tamanho
![]() . Já na abordagem para trás, inicia-se com um conjunto de avaliação
contendo todas as características disponíveis e, nas iterações do algoritmo,
são excluídas características até que esse conjunto fique com o tamanho
. Já na abordagem para trás, inicia-se com um conjunto de avaliação
contendo todas as características disponíveis e, nas iterações do algoritmo,
são excluídas características até que esse conjunto fique com o tamanho
![]() . Em geral, podem-se dizer que os métodos para frente são mais rápidos
que seus equivalentes para trás, pois o custo de medição da função
critério em conjuntos de características grandes é maior que o custo em
conjuntos pequenos [Jain and Zongker, 1997]. Porém, quando o valor de
. Em geral, podem-se dizer que os métodos para frente são mais rápidos
que seus equivalentes para trás, pois o custo de medição da função
critério em conjuntos de características grandes é maior que o custo em
conjuntos pequenos [Jain and Zongker, 1997]. Porém, quando o valor de ![]() é próximo
de
é próximo
de ![]() , deve-se dar preferência à utilização dos métodos para trás.
, deve-se dar preferência à utilização dos métodos para trás.
Abaixo apresentamos as definições utilizadas nos trabalhos de [Pudil et al., 1994] e [Somol et al., 1999] na descrição dos métodos de busca seqüenciais.
Seja
![]() um subconjunto
de
um subconjunto
de ![]() características do conjunto
características do conjunto
![]() das
das
![]() características disponíveis, o valor
características disponíveis, o valor ![]() da função critério de seleção
de características, quando somente a
da função critério de seleção
de características, quando somente a ![]() -ésima característica
-ésima característica ![]() ,
,
![]() for utilizada, é
chamado de significância individual
for utilizada, é
chamado de significância individual
![]() da característica.
da característica.
A significância
![]() da característica
da característica ![]() ,
,
![]() no conjunto
no conjunto ![]() é definida por
é definida por
| (3.22) |
| (3.23) |
Nota: para ![]() , o termo significância de uma característica no conjunto
coincide com o termo significância individual.
, o termo significância de uma característica no conjunto
coincide com o termo significância individual.
Dizemos que a característica ![]() do conjunto
do conjunto ![]() é:
é:
| (3.24) |
Dizemos que a característica ![]() do conjunto
do conjunto
![]() é:
é:
| (3.26) |
| (3.27) |
Seja ![]() genericamente uma tupla de
genericamente uma tupla de ![]() características, o valor
da função critério
características, o valor
da função critério ![]() , quando somente as características
, quando somente as características
![]() forem utilizadas, será chamado significância
individual
forem utilizadas, será chamado significância
individual ![]() da
da ![]() -tupla de características.
-tupla de características.
A significância
![]() da
da ![]() -tupla de características
-tupla de características
![]() no conjunto
no conjunto ![]() é
definida por
é
definida por
| (3.28) |
A significância
![]() da
da ![]() -tupla de características
-tupla de características
![]() ,
,
![]() no conjunto
no conjunto
![]() em relação ao conjunto
em relação ao conjunto ![]() é definida por
é definida por
| (3.29) |
Denotamos por ![]() a
a ![]() -ésima tupla contida no conjunto de todas as
-ésima tupla contida no conjunto de todas as
![]()
![]() -tuplas possíveis de
-tuplas possíveis de
![]() . Pode-se
dizer que a
. Pode-se
dizer que a ![]() -tupla de características
-tupla de características ![]() do conjunto
do conjunto ![]() é:
é:
| (3.30) |
| (3.31) |
Dizemos que a ![]() -tupla de características
-tupla de características ![]() do conjunto
do conjunto
![]() é:
é:
| (3.32) |
| (3.33) |
Nota: para ![]() , todos os termos relacionados com o significado de
, todos os termos relacionados com o significado de ![]() -tuplas de
características coincidem com os termos relacionados com a significância
individual de uma característica.
-tuplas de
características coincidem com os termos relacionados com a significância
individual de uma característica.
A seguir apresentamos a descrição dos principais métodos de seleção de características
determinísticos de solução única.
Melhores Características Individuais
O método de seleção de características pelas melhores caracteríticas
individuais consiste na avaliação de todas as características tomadas
individualmente e seleção das ![]() melhores. O algoritmo abaixo
detalha esse método. Note que, para fim de facilitar a exposição, o parâmetro
melhores. O algoritmo abaixo
detalha esse método. Note que, para fim de facilitar a exposição, o parâmetro
![]() dos conjuntos
dos conjuntos ![]() foi omitido nesse e nos próximos algoritmos, pois o
valor de
foi omitido nesse e nos próximos algoritmos, pois o
valor de ![]() varia conforme a execução dos algoritmos e os algoritmos podem
ser chamados com conjuntos de diferentes tamanhos.
varia conforme a execução dos algoritmos e os algoritmos podem
ser chamados com conjuntos de diferentes tamanhos.
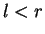
Como as características são
avaliadas individualmente, esse método não é classificado nem como para
frente, nem como para trás.
Trata-se de um método bastante intuitivo e computacionalmente simples, mas que
não garante que o melhor subconjunto seja determinado, pois algumas
características podem ser boas tomadas individualmente, mas podem formar um
conjunto ruim quando associadas entre si. Outros detalhes sobre esse método
encontram-se em [Jain and Zongker, 1997,Theodoridis and Koutroumbas, 1999]
Busca Seqüencial para Frente (SFS)
O método de busca seqüencial para frente, como o próprio nome diz, é um método
botton-up. Dado um conjunto de características já selecionadas
(inicialmente nulo), a cada iteração é seleciona a característica que, unida
ao conjunto determinado pela iteração anterior, produz o melhor resultado da
função critério. Essa característica é adicionada ao conjunto de
características anterior e uma nova iteração é realizada. São realizadas ![]() iterações. O algoritmo a seguir detalha esse processo,
devem-se assumir que inicialmente
iterações. O algoritmo a seguir detalha esse processo,
devem-se assumir que inicialmente
![]() .
.
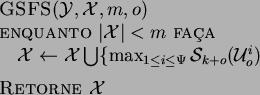
Observa-se que a instrução
![]() não foi incluída no algoritmo da função SFS(
não foi incluída no algoritmo da função SFS(![]() ), pois
essa função será utilizada posteriormente para conjuntos não vazios. Isso
repetir-se-á na função SBS(
), pois
essa função será utilizada posteriormente para conjuntos não vazios. Isso
repetir-se-á na função SBS(![]() ) a seguir.
) a seguir.
A desvantagem desse método é que, uma vez que uma característica tenha sido selecionada, ela não pode ser descartada do subconjunto ótimo, o que pode proporcionar o chamado efeito nesting. O efeito nesting ocorre quando o subconjunto ótimo não contém elementos do conjunto já selecionado, o que impossibilita que seja obtido o conjunto de características ótimo.
A principal vantagem da busca seqüencial para frente é o custo computacional
quando se deseja obter conjuntos pequenos em relação ao total de
caracteríscias. Outros detalhes a respeito desses métodos podem ser
encontrados em [Jain and Zongker, 1997,Theodoridis and Koutroumbas, 1999].
Busca Seqüencial para Trás (SBS)
O algoritmo de busca seqüencial para trás é uma versão top-down do algoritmo anterior. A
diferença entre SBS e SFS é que o SBS é iniciado com o conjunto de
características completo (contendo todas as ![]() características) e vai
eliminando as menos importantes, ou seja, as que menos alteram a função
critério quando são eliminadas. O algoritmo a seguir detalha esse processo,
devem-se assumir que inicialmente
características) e vai
eliminando as menos importantes, ou seja, as que menos alteram a função
critério quando são eliminadas. O algoritmo a seguir detalha esse processo,
devem-se assumir que inicialmente
![]() .
.
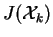
Assim como o método de busca seqüencial para frente, a desvantagem desse método é que, uma vez eliminada uma característica, ela não retornará ao subconjunto ótimo novamente. Como conseqüência, também pode ocorrer o efeito nesting caso o melhor subconjunto contenha alguma das características que foram eliminadas.
A principal vantagem desse método é o custo computacional, quando se deseja
obter conjuntos grandes em relação ao total de características. Outros
detalhes sobre esse método encontram-se em [Jain and Zongker, 1997,Theodoridis and Koutroumbas, 1999].
Mais l - Menos r (PTA) [Somol et al., 1999,Theodoridis and Koutroumbas, 1999]
O método mais l - menos r, cujo nome original é
``Plus ![]() - Take Away
- Take Away ![]() '' (PTA), foi
criado visando a evitar o efeito nesting. Basicamente, em cada iteração,
primeiro o algoritmo adiciona
'' (PTA), foi
criado visando a evitar o efeito nesting. Basicamente, em cada iteração,
primeiro o algoritmo adiciona ![]() elementos ao conjunto de características
usando o método de seleção para frente (SFS) e, posteriormente, elimina
elementos ao conjunto de características
usando o método de seleção para frente (SFS) e, posteriormente, elimina ![]() características usando a busca seqüencial para trás (SBS). Os valores de
características usando a busca seqüencial para trás (SBS). Os valores de ![]() e
e
![]() devem ser determinados pelo usuário. Na versão botton-up,
devem ser determinados pelo usuário. Na versão botton-up, ![]() deve
ser maior que
deve
ser maior que ![]() . Já na versão top-down,
. Já na versão top-down, ![]() . Segue o algoritmo que
detalha esse processo:
. Segue o algoritmo que
detalha esse processo:
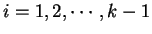
Conforme mencionado, esse método de busca evita o problema de nesting,
mas com ele surge um novo problema: a determinação dos valores de ![]() e
e
![]() . Se forem tomados valores muito pequenos, é possível que o problema nesting não seja evitado. Por outro lado, se os valores de
. Se forem tomados valores muito pequenos, é possível que o problema nesting não seja evitado. Por outro lado, se os valores de ![]() e
e ![]() forem
muito grandes, o algoritmo torna-se muito lento.
forem
muito grandes, o algoritmo torna-se muito lento.
Algoritmos de Busca Seqüencial Generalizada (GSFS e GSBS) [Somol et al., 1999,Theodoridis and Koutroumbas, 1999]
Os algoritmos de busca seqüencial generalizada inserem (no caso do GSFS) ou removem (no caso do GSBS) tuplas (subconjuntos) de características ao invés de o fazerem com apenas uma característica por iteração. Para possibilitar o funcionamento dos algoritmos generalizados, devem-se utilizar funções que determinam a significância de tuplas.
Os dois algoritmos de busca generalizada mais conhecidos são os seguintes:
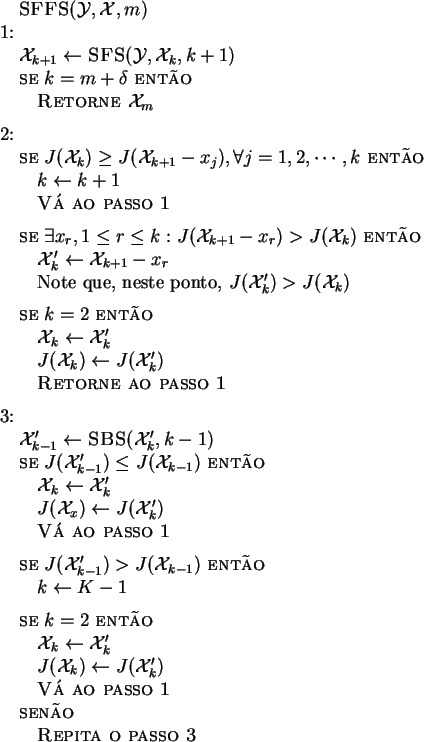
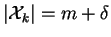
Além desses algoritmos, há também uma versão generalizada do algoritmo PTA, em que, para cada passo, ao invés de serem inseridas ou excluídas características individuais, são avaliadas tuplas de tamanho definido pelo usuário (para frente e para trás). Esse algoritmo proporciona resultados muito próximos do resultado ótimo, mas seu custo computacional pode torná-lo proibitivo em conjuntos de características grandes [Pudil et al., 1994].
Como esses algoritmos inserem ou removem tuplas de características ao invés de
características individuais, a probabilidade de ocorrer o efeito nesting
é reduzida. Porém, o problema da escolha do tamanho dessas tuplas (![]() ) é
fundamental para a obtenção do equilíbrio entre tempo de execução e qualidade
dos resultados. Quando o tamanho das tuplas for muito grande, o algoritmo
torna-se muito lento. Por outro lado, quando esse valor for pequeno, os resultados se
aproximam das versões não generalizadas desses algoritmos.
) é
fundamental para a obtenção do equilíbrio entre tempo de execução e qualidade
dos resultados. Quando o tamanho das tuplas for muito grande, o algoritmo
torna-se muito lento. Por outro lado, quando esse valor for pequeno, os resultados se
aproximam das versões não generalizadas desses algoritmos.
Métodos de Busca Seqüencial Flutuante (SFSM)
Os métodos de busca seqüencial flutuante para frente e para trás, propostos em [Pudil et al., 1994] podem ser vistos como generalizações do método mais l - menos r, em
que os valores de ![]() e
e ![]() são determinados e atualizados dinamicamente.
Como os próprios nomes dizem, o método de busca para frente (SFFS) é a versão botton-up, enquanto o de busca para
trás (SFBS), top-down.
são determinados e atualizados dinamicamente.
Como os próprios nomes dizem, o método de busca para frente (SFFS) é a versão botton-up, enquanto o de busca para
trás (SFBS), top-down.
O fluxograma da figura 3.14 resume o funcionamento da versão para frente desse algoritmo.
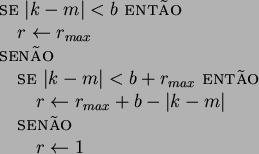
Pode-se notar que a condição de parada é que
![]() , em que
, em que
![]() é um valor de tolerância que é utilizado para que o algoritmo não
pare na primeira vez em que o conjunto
é um valor de tolerância que é utilizado para que o algoritmo não
pare na primeira vez em que o conjunto ![]() tenha tamanho
tenha tamanho ![]() , pois o
problema de nesting só pode ser evitado se forem realizados cálculos com
, pois o
problema de nesting só pode ser evitado se forem realizados cálculos com ![]() .
Normalmente utiliza-se um valor pequeno para
.
Normalmente utiliza-se um valor pequeno para ![]() (por exemplo,
(por exemplo, ![]() ).
).
A versão top-down desse algoritmo (SFBS) é bastante análoga a esse,
diferenciando-se somente na ordem em que os algoritmos SFS e SBS são
executados e em alguns critérios de avaliação dos conjuntos. Obviamente, no
SFBS, inicia-se com ![]() .
.
Esses métodos proporcionam soluções muito próximas da solução ótima com um
pequeno custo computacional.
Segundo Jain et al. [Jain and Zongker, 1997,Jain et al., 2000], esses são os métodos que melhor combinam tempo de execução com qualidade dos resultados.
Métodos Adaptativos de Busca seqüencial flutuante [Somol et al., 1999] (ASFSM)
Os métodos adaptativos de busca seqüencial flutuante para frente e para trás (ASFFS e ASFBS) foram construídos como uma evolução dos métodos de busca seqüencial flutuante (SFSM) de forma a tornar o algoritmo generalizado, adicionando-se ou removendo-se tuplas de características, ao invés de características individuais.
Tomando-se o algoritmo SFFS como exemplo, podem-se notar que somente os passos para trás são condicionais e somente esses permitem que o conjunto de características de um determinado tamanho seja melhorado. Por outro lado, os passos para frente não podem ser condicionais, pois se eles fossem, o algoritmo poderia teoricamente cair em um ciclo infinito (repetindo a adição condicional e remoção condicional de características). Por não serem condicionais, os passos para frente podem encontrar um subconjunto que é pior que o melhor de uma certa dimensão encontrado em iterações anteriores.
Para eliminar esse problema, se o passo para frente encontrar um subconjunto que é pior que o melhor de todos encontrado em um passo anterior, deve-se descartar o subconjunto atual e considerar o melhor subconjunto como o conjunto atual. Essa troca violenta entre o conjunto atual e o melhor conjunto encontrado não proporciona um ciclo infinito, pois esse caso só ocorre quando o melhor conjunto de características foi encontrado em um passo para trás.
Os métodos ASFSM (adaptativos seqüenciais flutuantes) não são simples
generalizações dos métodos SFSM, pois, além de inserirem ou excluírem tuplas
de características em seus passos, o tamanho dessas tuplas também é
determinado dinamicamente. São realizados testes com tuplas de vários tamanhos para
determinar-se a solução, mas, para limitar o tempo de execução do algoritmo, o
usuário deve definir o tamanho máximo absoluto das tuplas,
![]() . Para tornar o algoritmo mais eficiente, há um mecanismo que faz com
que o tamanho das tuplas seja inversamente proporcional à distância entre o
tamanho do conjunto sendo avaliado no passo atual (conjunto atual) e o tamanho final
. Para tornar o algoritmo mais eficiente, há um mecanismo que faz com
que o tamanho das tuplas seja inversamente proporcional à distância entre o
tamanho do conjunto sendo avaliado no passo atual (conjunto atual) e o tamanho final
![]() . Assim, quando os conjuntos sendo avaliados são muito menores ou muito
maiores que
. Assim, quando os conjuntos sendo avaliados são muito menores ou muito
maiores que ![]() , o ASFM é mais rápido, pois são inseridas ou excluídas tuplas
menores de características. Com isso, o algoritmo chega mais rápido a um
conjunto atual de tamanho próximo de
, o ASFM é mais rápido, pois são inseridas ou excluídas tuplas
menores de características. Com isso, o algoritmo chega mais rápido a um
conjunto atual de tamanho próximo de ![]() e vai aumentando a precisão da busca.
Um outro parâmetro que deve ser definido pelo usuário é
e vai aumentando a precisão da busca.
Um outro parâmetro que deve ser definido pelo usuário é ![]() , o
qual é usado para determinar a relação entre o tamanho do conjunto atual e o
tamanho máximo das tuplas. Assim, os parâmetros
, o
qual é usado para determinar a relação entre o tamanho do conjunto atual e o
tamanho máximo das tuplas. Assim, os parâmetros ![]() ,
, ![]() e
e ![]() são
utilizados para determinar o tamanho máximo das tuplas para a busca no
conjunto atual, sendo
são
utilizados para determinar o tamanho máximo das tuplas para a busca no
conjunto atual, sendo ![]() o tamanho atual da tupla. O algoritmo a seguir descreve como
o tamanho atual da tupla. O algoritmo a seguir descreve como ![]() é calculado durante
a execução do ASFSM:
é calculado durante
a execução do ASFSM:
A determinação dos valores de ![]() e
e ![]() não é automática. Porém esses
parâmetros não são tão críticos em relação à execução do método e de seus resultados quando comparados
com os parâmetros
não é automática. Porém esses
parâmetros não são tão críticos em relação à execução do método e de seus resultados quando comparados
com os parâmetros ![]() (tamanho das tuplas, no caso dos algoritmos
generalizados tradicionais),
(tamanho das tuplas, no caso dos algoritmos
generalizados tradicionais), ![]() e
e ![]() (no caso do método PTA). Uma
característica importante desse método é que, se
(no caso do método PTA). Uma
característica importante desse método é que, se ![]() , ele é executado
exatamente da mesma maneira que os métodos SFSM, o que faz com que a
desigualdade a seguir seja sempre válida:
, ele é executado
exatamente da mesma maneira que os métodos SFSM, o que faz com que a
desigualdade a seguir seja sempre válida:
| (3.34) |
Na seção 5.2.1 e no artigo [Campos et al., 2000c], mostramos os testes e resultados obtidos da comparação desses dois métodos para um problema de seleção de características com dados reais.
Recentemente, o grupo de pesquisa de Pudil (Academy of Sciences of the Czech Republic), criador dos métodos SFSM e ASFSM, propôs novos algoritmos de busca para seleção de características [Kittler et al., 2001]. Dentre eles, os principais métodos são os seguintes: