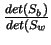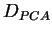A análise de discriminantes lineares (LDA), também conhecidos como discriminantes lineares de Fisher, é uma técnica que se tornou muito comum para reconhecimento de faces, principalmente a partir de 1997, com a publicação do artigo [Belhumeur et al., 1997]. Nesse artigo, os autores comparam PCA com LDA e mostram que o espaço de características criado pela transformação LDA proporcionou resultados de classificação muito melhores que o espaço criado pela transformada PCA para o reconhecimento de pessoas em imagens com grandes variações de iluminação.
Como pode-se observar na seção 3.2.2, a transformada de PCA é um método linear não supervisionado de extração de características que maximiza o espalhamento dos padrões no espaço de características, independentemente da classe em que esses pertencem [Jain et al., 2000]. Essas características possibilitam a ocorrência de problemas como aquele ilustrado nas figuras 3.7, 3.8 e 3.9. Para evitar tais problemas, podem ser aplicados algoritmos de seleção de características ou utilizar extratores de características que se baseiam em informações da distribuição das classes no espaço original.
Através de LDA, esses problemas podem ser evitados, pois trata-se de um método que utiliza informações das categorias associadas a cada padrão para extrair linearmente as características mais discriminantes. Em LDA, a separação inter-classes é enfatizada através da substituição da matriz de covariância total do PCA por uma medida de separabilidade como o critério Fisher.
Matematicamente, para todos os exemplos de todas as classes, define-se duas medidas:
O objetivo é maximizar a medida inter-classes e minimizar a medida
intra-classes. Uma maneira de fazer-se isso é maximizar a taxa
![]() . A vantagem de se usar essa taxa é que foi provado
[Fisher, 1938] que, se
. A vantagem de se usar essa taxa é que foi provado
[Fisher, 1938] que, se ![]() é uma matriz não singular (com determinante não nulo), então essa taxa é maximizada quando os vetores colunas da matriz de transformação
é uma matriz não singular (com determinante não nulo), então essa taxa é maximizada quando os vetores colunas da matriz de transformação ![]() são os autovetores de
são os autovetores de
![]() .
.
Pode ser provado que: (1) há no máximo ![]() autovetores e, então, o limite
superior de
autovetores e, então, o limite
superior de ![]() é
é ![]() , e (2) são requeridos no mínimo
, e (2) são requeridos no mínimo ![]() exemplos de
treinamento para garantir que
exemplos de
treinamento para garantir que ![]() não se torne singular (o que geralmente é
impossível em aplicações práticas). Para resolver isso, [Belhumeur et al., 1997]
propuseram a utilização de um espaço intermediário, o qual pode ser o espaço
criado pela transformada PCA. Então, o espaço
não se torne singular (o que geralmente é
impossível em aplicações práticas). Para resolver isso, [Belhumeur et al., 1997]
propuseram a utilização de um espaço intermediário, o qual pode ser o espaço
criado pela transformada PCA. Então, o espaço ![]() -dimensional original é projetado em um espaço
-dimensional original é projetado em um espaço ![]() -dimensional intermediário usando PCA e, posteriormente, em um espaço
-dimensional intermediário usando PCA e, posteriormente, em um espaço ![]() -dimensional, usando LDA.
-dimensional, usando LDA.
Em geral, essa abordagem possibilita a obtenção de resultados melhores que o PCA para redução de dimensionalidade. A figura 3.10 mostra o caso de um espaço de características bidimensional com duas classes. Nesse espaço, caso seja realizada a redução para uma dimensão, a projeção no primeiro componente principal (PCA) acarreta um espaço de característica que proporciona uma alta taxa de erro. Já a projeção no primeiro discriminante linear (LDA) proporcionará a taxa de acerto de 100%. Nesse exemplo, supõe-se a utilização do classificador de vizinho mais próximo.
Além desse exemplo, no caso ilustrado na figura 3.4, o discriminante linear de Fisher iria determinar, como primeiro vetor da base, exatamente aquele que foi determinado pelo segundo auto-vetor no caso de PCA, ou seja, o vetor cujo auto-valor é 0.0014 na figura 3.8.
Porém, [Martinez and Kak, 2001] mostraram recentemente que o desempenho de PCA pode
ser superior ao de LDA quando o tamanho do conjunto de treinamento ![]() é
pequeno. Esses resultados foram obtidos a partir de testes para reconhecimento de faces em uma base de imagens de 126 pessoas, sendo 26 imagens por pessoa, com problemas de oclusão e variações em expressões faciais. Foram realizadas duas baterias de testes, a primeira com poucas imagens de treinamento por pessoa (somente 2) e a segunda com várias imagens de treinamento (13). Na maioria dos experimentos com conjunto de treinamento pequeno, o desempenho do PCA foi superior ao do LDA. Por outro lado, em todos os testes com conjunto de treinamento grande, o desempenho do LDA foi superior ao do PCA.
é
pequeno. Esses resultados foram obtidos a partir de testes para reconhecimento de faces em uma base de imagens de 126 pessoas, sendo 26 imagens por pessoa, com problemas de oclusão e variações em expressões faciais. Foram realizadas duas baterias de testes, a primeira com poucas imagens de treinamento por pessoa (somente 2) e a segunda com várias imagens de treinamento (13). Na maioria dos experimentos com conjunto de treinamento pequeno, o desempenho do PCA foi superior ao do LDA. Por outro lado, em todos os testes com conjunto de treinamento grande, o desempenho do LDA foi superior ao do PCA.
A figura 3.11 ilustra um caso em que o desempenho de PCA é
superior ao de LDA. Trata-se de um exemplo com duas classes, cujos padrões são
representados por `![]() ' para a classe A e `o' para a classe B. A
distribuição dessas classes está ilustrada pelas elipses
pontilhadas. Usando-se os dois exemplos de treinamento por classe mostrados na
figura, o primeiro vetor do espaço PCA obtido está indicado por `PCA', e a
fronteira de decisão proporcionada por esse método está indicada por
`
' para a classe A e `o' para a classe B. A
distribuição dessas classes está ilustrada pelas elipses
pontilhadas. Usando-se os dois exemplos de treinamento por classe mostrados na
figura, o primeiro vetor do espaço PCA obtido está indicado por `PCA', e a
fronteira de decisão proporcionada por esse método está indicada por
`![]() '. Já o primeiro vetor do espaço LDA está indicado por `LDA', e sua
respectiva fronteira de decisão, por '
'. Já o primeiro vetor do espaço LDA está indicado por `LDA', e sua
respectiva fronteira de decisão, por '![]() '. Nota-se claramente que, caso
seja reduzida a dimensionalidade para 1, pela
distribuição das classes, a fronteira de decisão criada pelo PCA é superior
à do LDA3.3.
'. Nota-se claramente que, caso
seja reduzida a dimensionalidade para 1, pela
distribuição das classes, a fronteira de decisão criada pelo PCA é superior
à do LDA3.3.
Além de requerer um conjunto de treinamento grande, outro problema dessa abordagem é sua incapacidade de obter bons resultados se aplicada a classes com distribuição côncava e com interseção com outras classes, como no caso de dados com distribuição similar aos da figura 3.12 (em todas as dimensões). Nesse caso, a transformada vai tentar minimizar a variação intra-classe e maximizar a variação inter-classes, o que pode resultar em uma representação dos dados pior do que a original para classificadores como os K-vizinhos mais próximos. Isso reforça a necessidade da utilização de algoritmos de seleção de características.
Maiores detalhes a respeito de discriminantes lineares podem ser obtidos através das referências [Theodoridis and Koutroumbas, 1999] e [Fisher, 1938].